Tools for the era of experience
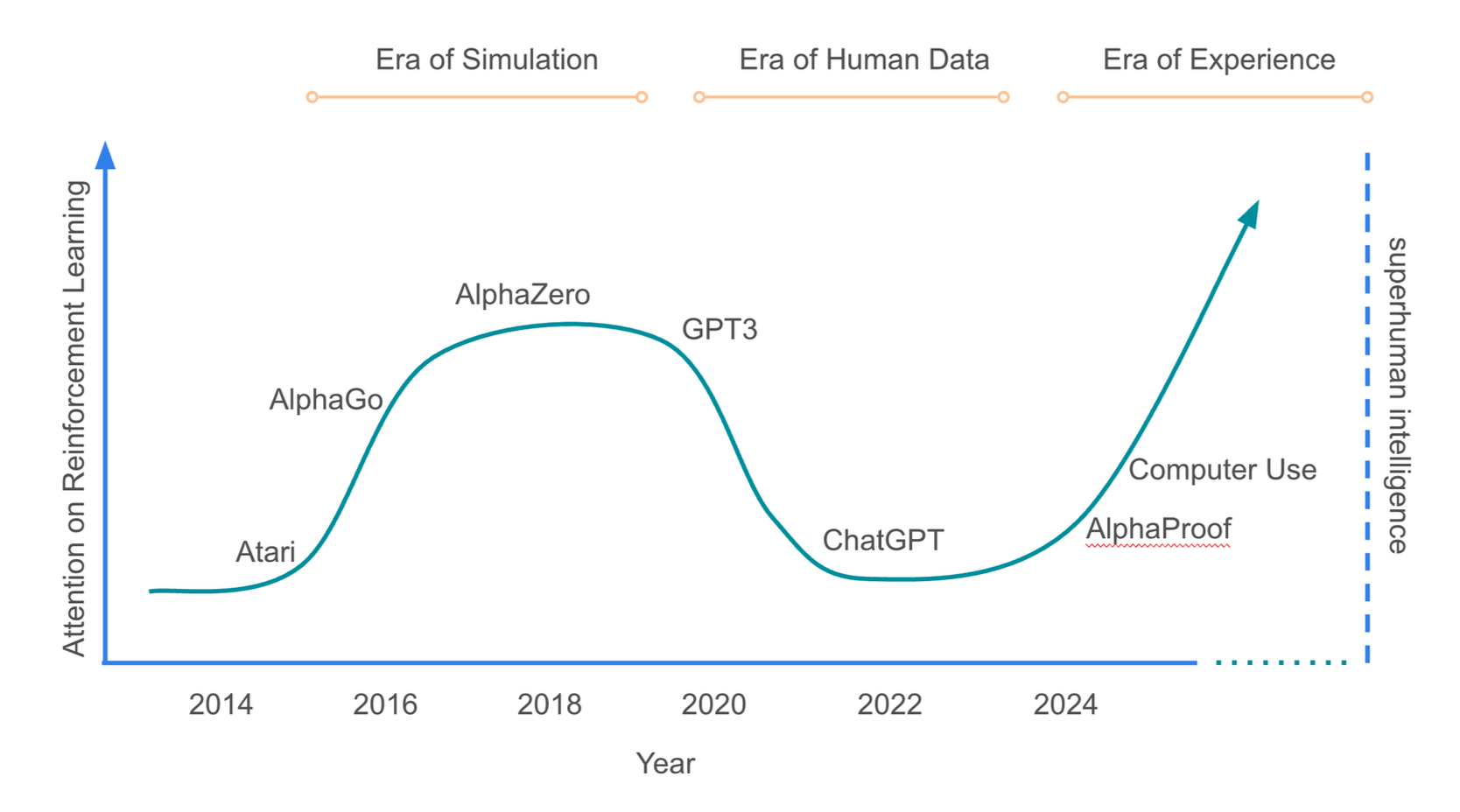
I recently read a beautiful chapter from the unpublished book “Designing an Intelligence” by David Silver and Rich Sutton. It’s titled “Welcome to the Era of Experience” and you can read it here. The basic gist is this: current LLMs, trained on the sum of human knowledge, are approaching a ceiling. High-quality human data is a finite resource, and these models can only reproduce human capabilities, not truly surpass them.
If you trained an LLM 300 years ago, it might reason using Newtonian mechanics. If you trained it 1000 years ago, it might reason in theistic terms. Today’s models inherit our blind spots. They’re sophisticated echo chambers of whatever worldview was baked into their training data. An LLM can give you brilliant answers about quantum mechanics, but it can’t discover the next paradigm shift in physics. It’s like asking a master librarian to invent new science. They can tell you everything that’s been written, but they can’t run the experiment that proves everyone wrong.
The authors argue that for AI to accelerate beyond our current school of thought, it needs to interact with the world. It needs to form hypotheses, run experiments, observe the results, and update its understanding. It must be grounded in reality to overturn our flawed assumptions. Without this grounding, an agent, no matter how sophisticated, will just be an echo chamber.
What next? - Experiential learning
The next wave of AI agents will learn by doing. This is similar to how AlphaGo played millions of games against itself to surpass human Go masters. This new era of training will be defined by a few key characteristics: ongoing streams of experience instead of short, disconnected sessions; autonomous actions in the real world, not just text responses; and rewards grounded in real-world outcomes, not just human preferences.
The bitter lesson from decades of AI research is that the winning models are the ones that scale best with compute and data, not those with clever, human-designed rules. This is Tesla’s bet in a nutshell: no LiDAR, no hard-coded rules, just vision and a learning model fed by fleet data. It’s also why OpenAI and others shifted from small, curated datasets to massive reinforcement learning loops.
But before these brute-force models got good enough, everyone needed high-quality, structured data from labeling, RLHF, and safety tuning. This was the labor-dependent middle layer of the stack. If the future is fully self-supervised learning in real or simulated environments, then data labeling companies start to look like bad long-term bets. Infinite labeling doesn’t scale past a certain quality threshold.
Part of my job is to figure out where value will be created in this new paradigm. If OpenAI, Anthropic, and xAI can brute-force general intelligence with their compute, what can a startup possibly build that they can’t just replicate? What can we build that Sam Altman and Sundar Pichai cannot?
What to build for this era then?
The Silver & Sutton paper suggests that compute plus environment beats compute plus labels. If that’s true, the game isn’t just about who has the most GPUs. It’s about who controls the richest streams of experiential data.
While the big labs can throw infinite compute at general intelligence, they can’t be everywhere at once. They can’t own every workflow, every sensor, every domain-specific feedback loop. That’s where the opportunity lies.
Environment
Remember how Tesla’s real moat isn’t just their AI team but their fleet? Every Tesla on the road is a data collector, experiencing edge cases that can’t be simulated. The winners in the era of experience won’t just build better models; they’ll build proprietary environments where agents can learn things no one else can.
Take construction sites. A startup could deploy cheap sensors across projects to track worker movements, equipment usage, material flow, and safety incidents. An agent learning in this environment could discover patterns humans miss, like noticing that accidents spike when certain equipment configurations are used together. The construction companies can’t build this themselves, and OpenAI can’t access this data without a physical deployment.
Or consider hospital emergency rooms. A startup could build the connective tissue between EMR systems, vital sign monitors, and patient flow systems. The agent would experience the ER in real-time, learning which triage decisions lead to better outcomes months later. Google can train the next big model, but they can’t access your hospital’s real-time sensor feed.
For non-hardware domains, legacy tech companies might have an edge. They already have a wealth of simulation data from their users and are best positioned to train these agents. Here is an excerpt from the Pleias.fr blog on training LLM agents.

What else to build:
Industrial automation agents that learn from real-world factory floor data, like an agent that watches CNC machines 24/7 to predict failures from sound patterns or optimizes cutting paths through trial and error.
Agricultural yield agents that use sensor data from greenhouses to control variables like temperature and nutrients, learning directly from which actions produce better crops.
The key is proprietary access to environments where cause-and-effect cycles play out. No amount of compute can simulate what happens when you change the fertilizer mix in a specific greenhouse.
Reward engineering
In the current paradigm, everyone is obsessed with prompt engineering. In the Era of Experience, the money will be in reward engineering.
Let me explain. Say you’re building an AI sales assistant. OpenAI’s version might optimize for user satisfaction scores. But what if your reward function is a composite: 30% close rate, 20% customer lifetime value, 20% time-to-close, and 30% post-sale NPS score measured six months later? Suddenly, your agent learns completely different behaviors. It might discover that slowing down the sales process for enterprise clients actually increases LTV.
These reward functions become proprietary knowledge. You’re programming business strategy directly into the agent’s learning process. A competitor can copy your UI, but they can’t copy the years of refined reward engineering that makes your agent act like a senior enterprise sales rep instead of a chatbot.
More examples:
Negotiation agents for B2B contracts: Define rewards based on a mix of deal closure rate, contract value, and long-term relationship health, measured by whether the client renews their contract a year later.
Therapy companion agents: Instead of optimizing for “did the user like this response?”, rewards are based on validated mental health metrics tracked over months with real therapists.
Code review agents: Optimize for a composite reward of “bugs caught before production,” “developer learning,” and “team velocity”—a mix no generic coding assistant will target. I’ve heard both Cursor and the Gemini team are working on this.
We’re already seeing early versions of this. Harvey, the legal AI, is supposedly building environments where agents practice contract negotiations with rewards based on deal outcomes months later. Chemistry VC also wrote a great post on this about RLaaS (Reinforcement Learning as a Service) companies, which you can find here.
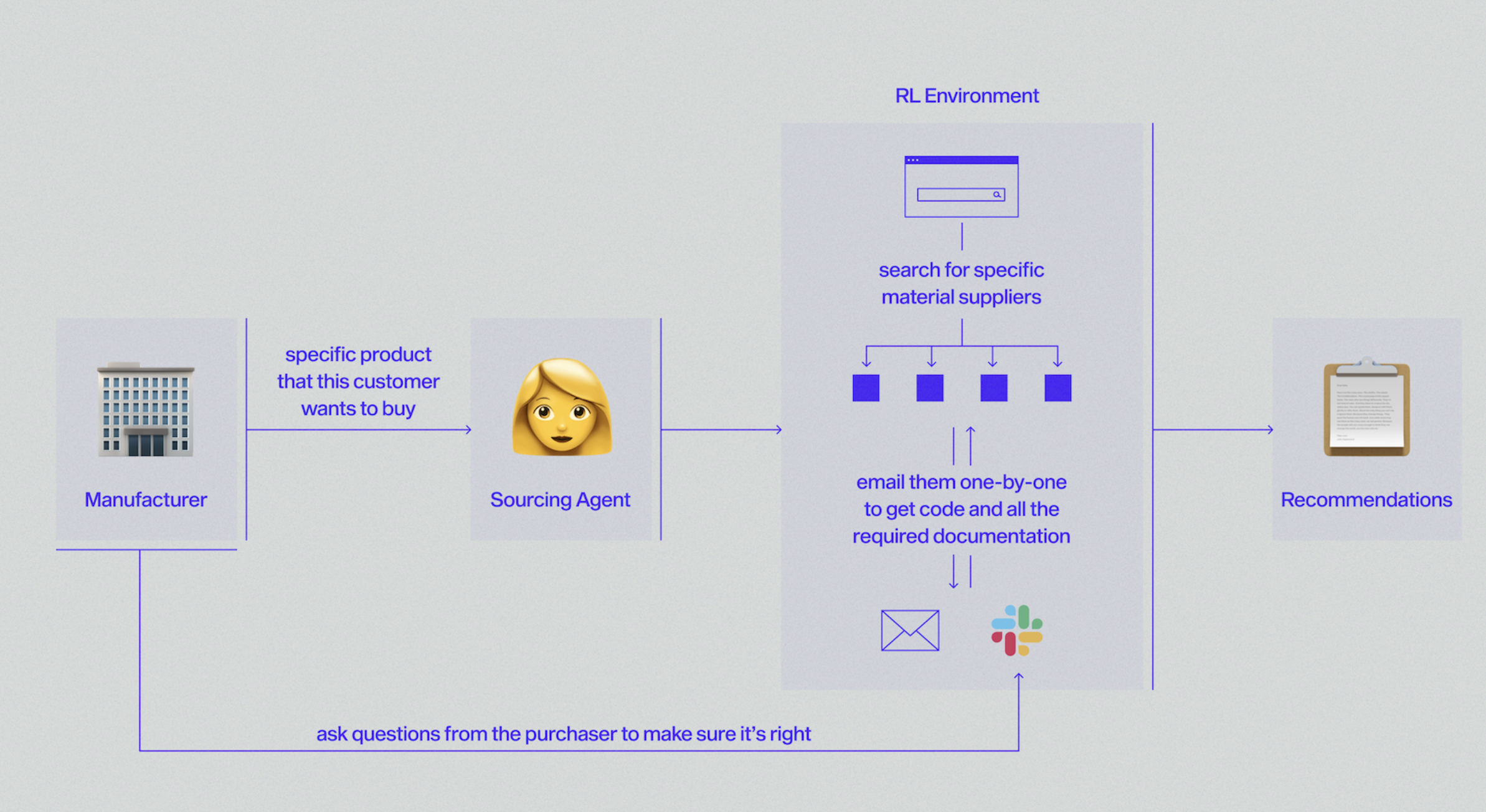
The real-world impact of this approach is exemplified by a case from Veris AI: an agent trained with RL to automate the complex, hours-long process of supplier negotiations. By training on realistic simulations of Slack and email conversations—complete with sensitive data—the agent learns optimal tone, questions to ask, and search strategies, dramatically outperforming prompt chaining or one-shot LLM attempts.
Interface changes
This one is subtle. The big labs will build general intelligence, but someone needs to own the last mile, the surfaces where agents interact with humans and systems.
Think of a Figma for AI Agents. Figma didn’t invent vector graphics, but they owned the interface where designers work. We need dashboards where product managers can spin up agents, define reward functions with visual tools, and monitor long-running workflows.
What to build:
Legal research terminals embedded in law firms that learn from which cases lawyers cite and which arguments actually win in court
Developer environment agents that live in your IDE and learn from your entire team’s workflow over months, going beyond simple coding assistants. Cursor and Windsurf are early examples.
Financial planning platforms where agents manage real portfolios and adapt to market movements and client life events—essentially, robo-advisors without fixed rules. These likely already exist inside hedge funds and prop trading shops.
Or take enterprise software. Salesforce might be disrupted by someone who builds the connective tissue that lets agents operate across CRM, email, calendar, and analytics tools. The moat is owning the interface where humans supervise and direct these agentic processes. This is where companies like Julep.ai are trying to build, though the monitoring and dashboard layer is still nascent.
Synthetic Worlds
The next generation of training data will also come from synthetic environments designed to train agents for specific tasks.
Imagine you’re training an agent for supply chain optimization. Instead of waiting for real disruptions, you build a high-fidelity simulation with weather patterns, geopolitical events, and port congestions. Your agent can experience a thousand supply chain crises before breakfast, learning strategies no human has ever tried. Lyric.tech is one company I know of building these kinds of causal inference models.
More synthetic world opportunities:
- Negotiation simulators - Multi-agent environments where AIs learn complex negotiation strategies through millions of simulated deals. Train agents that can handle edge cases no human negotiator has seen.
- Economic policy sandboxes - Simulate entire economies where agents try different fiscal policies and see long-term effects. Governments could use these to test policies before implementation.
The key insight is that OpenAI won’t build a niche supply chain simulator. But for a focused startup, that simulator becomes a data factory, churning out experience that’s worth more than all the text on the internet for that specific domain. ChemistryVC has another great post on this topic here.
What’s remarkable is that these agents are beginning to converge on human behavior, in some cases more accurately than traditional surveys when compared to real-world outcomes. Corporations and governments routinely spend hundreds of thousands of dollars and wait months to gather data from human panels. Synthetic research offers a faster, cheaper alternative—with the potential for a continuous stream of insight rather than discrete snapshots in time. Imagine being able to assess how much people would pay for your product, anticipate the impact of a new tax, or even predict election outcomes—in real time. This could fundamentally reshape how decisions are made across industries.
Frontier
The big labs are constrained by their visibility, regulation, and cultural commitments to safety. There’s a whole frontier of capabilities they won’t touch for years like stuff which operate in the gray zones.
- Adversarial security agents - Systems that actively probe networks, try exploits, and learn from what works. CrowdStrike + AlphaGo. Big labs won’t touch this. I dont know how much RL happens in the XBOW agent but its a good example.
- Persuasion optimization engines - Agents that learn what actually changes minds through A/B testing arguments, tracking belief changes. Useful for public health campaigns on the good side but can also be used for propaganda and ads. There is a big NSFW angle here too which is self explanatory.
- Financial exploit finders - Agents that trade in simulated markets, discover arbitrage opportunities, learn market microstructure. The stuff Renaissance Technologies does, but as a service. Pretty sure people building this already run their own prop trading shops.
A startup building “uncensored therapy agents” for specific populations might discover interaction patterns that actually help people more than our current “always honest, always safe” approach. Maybe the agent learns that for certain personality types recovering from addiction, a small tactical lie about recovery statistics prevents relapse better than brutal honesty.
So, what should you do?
Secure the telemetry monopoly now. Find a niche where you can instrument everything. Every action, every outcome. This data exhaust becomes your moat. A friend’s startup put sensors in commercial kitchens - they now know more about restaurant operations than anyone. While they are still figuring out what to do with this data, I am pretty sure this will become their moat in the long run.
Build reward engineering tools. The next TensorFlow but for reward function composition. Let domain experts define complex objectives without writing code.
Go full-stack on agents. Don’t build thin wrappers around GPT-5. Build the entire loop: perception, action, outcome measurement, and model update. Own the whole cycle.
Instrument for safety from day one. When your agent runs for months unsupervised, you need audit trails, rollback mechanisms, and kill switches. The first startup to make “safe autonomous agents” easy will win enterprise contracts.
The Bottom Line
The Era of Experience is a redistribution of power from the compute-rich to the data-rich. OpenAI has the GPUs, but you can own the environments. They have the models, but you can engineer the rewards. They have general intelligence, but you can own specific workflows.
If I had to place bets, I’d put chips on vertical-specific agent platforms that own the entire learning loop, and on the agent ops infrastructure that will be the Datadog for this new world.
The path forward is clear: Find a domain where experience matters. Instrument the hell out of it. Define rewards that align with real-world outcomes. Deploy agents that learn continuously.
The future isn’t just about bigger models eating more of the internet. It’s about smarter agents learning from richer experiences. They’ll build the intelligence. We’ll build the worlds it lives in.
If you are building anything relevant to what you read above, please reach out to me.