How to optimise latency for voice agents
Over the last week, I have been researching and reading about different horizontal platforms like Vapi, Retell and Bland to understand how they work behind the scenes. My main motivation was to 1) figure out the voice agent stack 2) see if there are any unsolved problems in the space and 3) look for interesting companies which I can then take up with my team at Accel for investing. Along the way, I learnt a fair bit about the importance of latency in building voice apps and how important is to achieve a sub ~800ms latency for end to end setups. It really makes or breaks the voice agent experience along with other things like interrupt and turn detection, mid-sentence redirection, etc and this posts looks at the all these considerations from a latency POV(and suggests tips) to build a kickass voice agent. To see how important is latency is in building voice applications, I vibe coded a small application to simulate how the user experience is for different latency configurations. You can play with it at comparevoiceai.com .
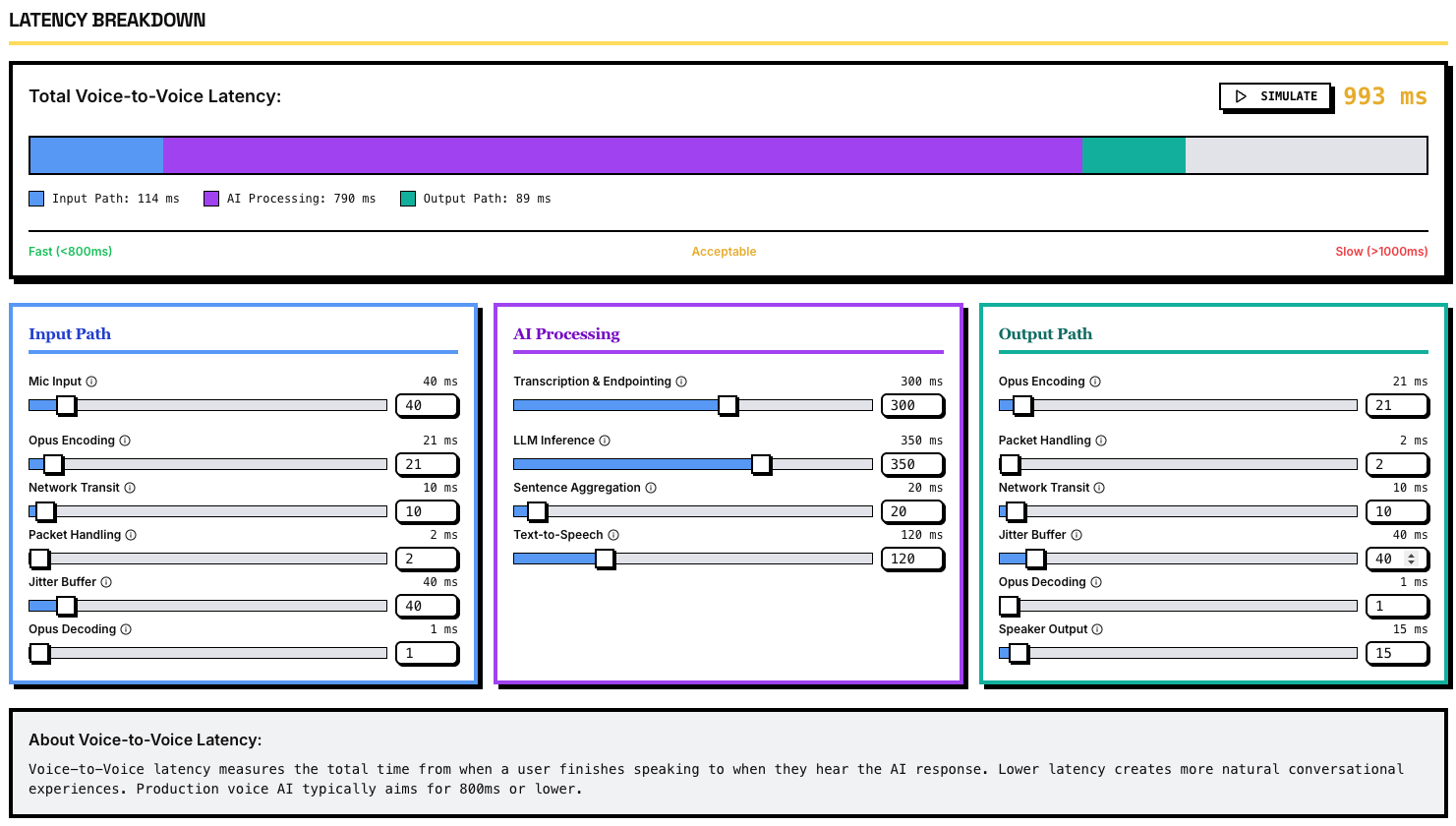
Most voice AI apps follow the below pattern. The user speaks into the microphone. THe audio is processed client side (noise compression, speaker isolation etc) and then piped with WebRTC (e.g., Daily) to a server, then Speed to Text (STT) models (like Deepgram) transcribes speech to text. The Dialogue/LLM layer turns that text into an appropriate reply transcript(probably calling other LLMs, function calls etc), which Text-to-Speech (TTS)—providers like ElevenLabs render as audio. A second WebRTC hop streams the audio back to the user, with each leg adding latency and failure points that orchestration must hide.

Achieving human-like responsiveness requires optimizations at every layer of this pipeline, especially in how we manage LLM context and system architecture. In the first section, we will look at all the methods we can use to cut latency on the central LLM block. If you want to learn more about choosing the right LLM provider for building your voice agents, you can read more on the blog post I wrote on the comparevoiceai.com website.
Link: Which LLM to choose for voice agents.
Semantic caching
Semantic caching stores previous queries and LLM answers so that semantically similar prompts can reuse results without a full model call. Unlike traditional key-value caching (which hits only on exact string matches), semantic caching uses embeddings to match queries by intent, not exact wording. For example, “What’s the home loan policy?” and “How does your company handle home loands?” have the same intent; a semantic cache would recognize their similarity and return a cached answer if available.
The system first converts an incoming prompt into a vector embedding that captures its meaning. It then performs a similarity search in a vector database (e.g. FAISS, Pinecone, Chroma) of past query embeddings. If a cached query with high similarity is found above a threshold, the system returns the stored answer instead of calling the LLM. On a cache miss, the entire voice pipeline is run normally. You will do make the LLM generate a response normally, and the new query+answer are added to the cache (storing both the text and its embedding for future comparisons). This approach turns LLM calls into a search problem.
One good thing for us is that Voice agents often faces repetitive or similar user requests (think FAQs or common dialogues). Semantic caching can dramatically cut response times for these cases. For instance, if a caller asks “When can I bring my car for servicing?” and later another caller asks “When is your car wash generally open?”, a semantic cache would detect the repetition and instantly serve the cached answer. This is especially useful for IVR or customer support bots. Moreover, caching can include multimodal artifacts ex. storing a generated TTS audio file along with the text. Production systems do this to skip TTS on repeats: on a cache miss you generate the text and audio, store both, and on a hit you return the cached text and a URL or ID for the prerecorded audio. The next time someone asks that question, the voice agent can play the pre-synthesized audio immediately instead of regenerating speech, saving hundreds of milliseconds.
Hitting the cache is far faster than a full LLM run. A self-hosted semantic cache can answer in ~50 ms (or ~200 ms via an API call) versus an LLM which might take seconds. This translates to a snappier dialogue and lower compute cost. In practical terms, even moderate reuse can yield big savings. Each cache hit avoids LLM token generation latency and also ensures consistent answers (the same question gets the same response every time ). Doing this in a very contextual manner is not easy. You don’t want to hit the cache for every related question and you want to give a personalised answer to the user. Here is the CTO of Hyperbound AI talking about choosing Vapi because of its great semantic caching abilities. (ignore the typo from the Tegus screenshot. Their STT is bad)

- Semantic caching has become a standard optimisation and an “easy win” these days though. Every horizontal provider gives the capability and even agent orchestration frameworks like Langchain give OOTB tooling for adding semantic caches to your tool calls. It’s important to scope the cache to each context or persona: e.g. maintain separate caches per voice agent or client to avoid mixing answers between different domains. It is generally recommended to filter personal data out of cached content and implementing cache invalidation rules (e.g. time-based eviction or manual resets for stale answers)
Prompt Optimisation Techniques
Feeding long conversation histories or verbose prompts into an LLM is a major source of latency. The more tokens the model must process, the longer it takes to produce a response. In this section, we will look at some tricks to minimise the prompt and complexity per request while making sure the context and functionality isn’t lost.
Prompt distillation and summary: Rather than resending the entire chat history each turn, distill older turns into a concise summary. For example, after a few exchanges, a voice agent can replace the detailed transcript of earlier dialogue with a one-sentence summary or extracted facts. This compresses memory so the prompt stays within a small window. The LLM only sees the essential bits of prior context, reducing token count. Automated recursive summarization of previous interactions (possibly using a smaller model or a background batch job) can maintain context implicitly.
- Another thing you can do it implement a rolling context window. A simple heuristic is to include only the last N turns of dialogue verbatim, and omit or summarize older turns as above. This creates a sliding window that “forgets” distant history except for a synopsis. Developers often keep the most recent user question and agent answer in full (since they’re directly relevant), and progressively trim earlier content. This dynamic prompt trimming ensures the prompt doesn’t grow past the model’s context length. It also helps latency: processing 500 tokens of relevant text is a lot faster than re-processing 5000 tokens of entire history every time.
For open ended voice applications, in real time, the system can decide what to include based on importance. For instance, if a user’s new query is on a new topic, the agent might drop irrelevant past context altogether. If the user references something from earlier, the agent can retrieve just that piece. You can do this with a RAG and maintening an index of the conversation history and fetch only the portions semantically related to the latest query (a form of hybrid dense/sparse retrieval for context). By combining keyword search (to catch explicit references) and embedding similarity (to catch topical relevance), the agent can cherry-pick which past utterances to feed the LLM. This hybrid retrieval ensures important context is present but extraneous chat is omitted.
- When conversations get very long, another trick is to periodically inject a “summary memory” back into the prompt and clear out raw dialogue. For example, after 10 turns, the system might insert: “Summary: [brief summary of discussion so far]” as a system or assistant message, then start a fresh context window with that summary plus the last Q&A. This compacts the state. Some systems maintain multiple summaries at different granularity (e.g. a running short-term summary updated every turn, and a more detailed long- term summary updated less frequently). Breaking context into chunks and summarizing each chunk can help the model recall older info without processing it repeatedly. These summaries themselves can be stored and retrieved when relevant (like notes).
Streaming and Overlap of STT, LLM, and TTS
Traditional voice agents operated in a strictly turn-based fashion: the user speaks, the system waits for them to finish, then processes the query, and finally speaks the response. This results in noticeable dead air while the user waits for the agent’s reply. Modern real-time architectures instead use streaming at each stage, overlapping tasks to eliminate idle gaps. The goal is to make the conversation feel fluid, as if the agent is listening and formulating a response almost simultaneously.
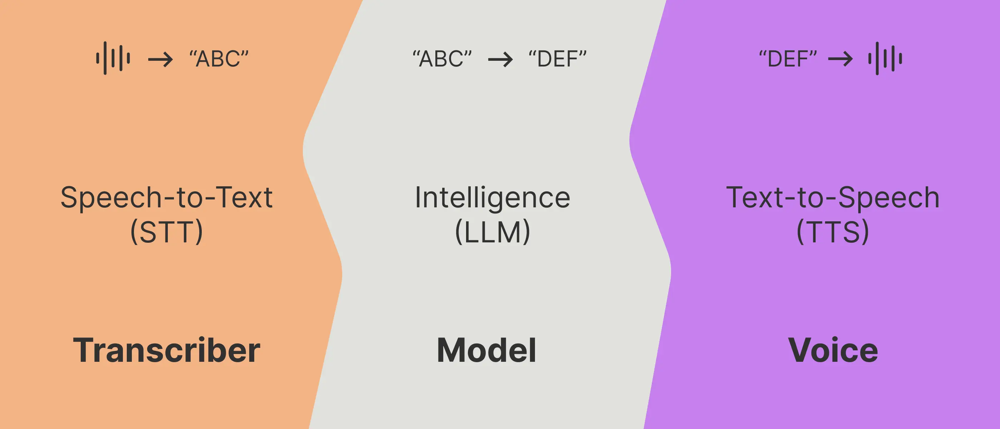
Streaming STT: Rather than buffering the entire user utterance, streaming speech-to-text transcribes audio on the fly. As the user speaks, partial text hypotheses are produced every tens of milliseconds. This allows the system to get a head start on understanding the query. By the time the user finishes speaking (or even before they finish), the agent may already have most of the text. For example, with a capable streaming STT, an utterance might be recognized with only ~200 ms delay from speech. Real-time voice agents use this to overlap listening and thinking: the LLM can start working as soon as it has enough of the utterance to guess the intent, without waiting for a full stop. I still remember watching Google’s Duplex demo in some I/O event. They were injecting “uh-huh” while still transcribing, to show the user they’re listening and make the overall experience very natural.
Nearly all modern LLM services (OpenAI, Anthropic, etc.) support streaming output, meaning the model generates tokens incrementally and sends them as they’re ready. This is crucial for latency – the user doesn’t need to wait for the entire answer to be formulated. My biggest gripe with this is that they don’t have any atomic methods to stream the function calls. You sometimes have to wait for the entire function block to stream before making the tool call which adds unnecessary latency. If your voice agent company has found a workaround around this, please reach out to me.
- Time-to-First-Token(TTFT) is a key metric here. Ideally, the LLM should emit the initial word of its answer within a fraction of a second so the TTS can begin.
Streaming text-to-speech (TTS) is the counterpart to streaming STT. Instead of waiting for the full generated sentence, advanced TTS systems can start synthesizing audio from the first chunk of text and continue as more text comes in. This means as soon as the LLM produces a few words, the agent’s voice can start speaking them. The overlap of LLM and TTS is crucial: if the model streams at (say) 20 tokens/sec and the TTS can synthesize just as fast, the spoken output will closely trail the model’s generation. Some architectures even interleave these so tightly that the end-to-end latency is basically TTFT + a small TTS buffer. In practice, many voice AI platforms (Retell, Bland, etc.) achieve extremely low response delay by pipelining in this way – e.g. Retell AI advertises ~600 ms end-to-end latency for a response. This likely includes a few hundred ms for STT, a couple hundred for LLM to start streaming, and another couple hundred for TTS to produce the first audio. By comparison, a non- streaming system might take 2–3 seconds before it even begins speaking(believe me, I vibe coded a dumb voice system last weekend). Streaming cuts that dramatically. One design pattern is to generate an answer sentence-by-sentence: as soon as the model has the first sentence, send it to TTS while the model works on the second sentence, and so on.
- Time-to-First-Byte(TTFB) is the key metric here. Ideally you want the TTS model to start speaking ASAP as soon as it receives the test
- How to choose a TTS model for your voice agent
Concurrent STT and response formuation: Real-time architectures strive for full-duplex interaction. The agent doesn’t strictly wait for the user to finish talking to begin its own processing. In fact, with the right design, an AI agent might even start responding before the user has finished their sentence (as humans sometimes do). Experimental systems (e.g. Meta’s Speech ReaLLM research aim to make LLMs proactive – generating partial responses while input is still streaming in. In practice, most current voice agents are half-duplex with barge-in: the agent won’t talk over the user (except maybe to interject a short acknowledgment), but it will listen and prepare in parallel so it can reply immediately once the user stops. Achieving true full-duplex (both talking at once) is still an active research problem, but the trend is moving toward agents that feel less turn-based. For instance, one can simulate a bit of full-duplex by having the agent produce brief backchannels (“I see”, “mm-hmm”) during a long user monologue to show it’s engaged – this requires very low latency understanding so as not to mis-time these cues. As latency gets pushed down, these natural conversation behaviors become feasible.
- An effective pattern is staged processing: 1. While user speaks, stream audio to STT and buffer text. 2. Immediately on end-of-speech, send the accumulated text (or even the partial text before the end) to the LLM, which starts generating. 3. As soon as the first tokens are out, begin TTS. 4. If the user starts speaking again (barge-in), detect it and cut off TTS (more on that in the next section).
Startup and Warm up Latency Minimisation
Latency isn’t only about how fast the model generates tokens; it also includes any delays in starting up the model or service. In real-time voice interactions, even a one-time delay (like a cold start) can ruin the user experience on the first query. Therefore, systems must minimize initialization overhead and avoid cold starts during a session.
Warm prompting / priming: If using an API-based LLM (like OpenAI), the very first request in a session may incur extra latency (due to loading the model or caching the prompt). One trick is to send a lightweight “warm-up” query in advance. For example, some developers issue a dummy prompt (e.g. “ping”) to the LLM when a call begins or even periodically during idle times, just to keep the model instance warm. This can reduce latency for the real user queries that follow, since the model’s context cache is already initialized on the server. Essentially, you pay a tiny cost upfront to avoid a bigger delay later. Similarly, with on-prem models, doing a dry-run through the network and model path at startup (e.g. generating an empty response) can load weights into memory.
Many open-source inference servers allow you to maintain a session state between queries. If a voice conversation is ongoing, you can reuse the LLM’s internal cache of key/value attention states for the next turn instead of recomputing from scratch. You can feed the conversation as it grows and carry over the past_key_values to the next generate call. This means the model doesn’t have to re-encode the entire history each time – it incrementally continues generation. In a long back-and-forth dialogue, this can save significant time (the initial prompt is encoded once, then only new user input is encoded subsequently). Some inference engines (like vLLM) even support prefix caching: if you have a static system prompt or persona description at the start of every query, the engine can precompute its vectors and reuse them, rather than encoding that prompt text for every request. All these techniques reduce duplicated work on repeated or continuous queries, shaving off latency.
Avoid cold starts with warm pools: In a serverless or autoscaling scenario, cold start latency (loading a large model into RAM or spinning up a new GPU container) can be 10–30 seconds – obviously unacceptable for real-time voice. To combat this, ensure at least one instance of your model service is always running (a warm pool of instances). Cloud providers and frameworks allow configuring a minimum number of warm workers. Even if load is zero, keep one hot. This way the first request doesn’t pay the full load cost. Retell for example suggest using a high- priority pool or reserved capacity for low latency if your response times are creeping us. It’s better to incur a bit more cost keeping resources alive than to have a caller wait awkwardly while a model loads.
Fast model loading and lightweight models: Choose models and serving frameworks that start quickly. Smaller models (or quantized models) not only run faster, but also load faster from disk. For example, a 7B parameter model can be loaded in a couple of seconds on my macbook (24GB RAM M4 Pro), whereas a 32B model takes 10+ seconds to initialize. If you require a large model for quality, one idea is to defer using it for a second or two and initially use a smaller model for the very first reply. For instance, a voice assistant might use a fast 1.3B model to say a greeting like “Hello, how can I help you today?” instantly, while in the background loading the 13B model that will handle the actual query. The user hears the greeting (which buys time), and by the time they ask their question, the heavy model is ready. This kind of staged startup can mask latency by doing useful work (like greeting or collecting the user’s name) while loading the main model.
Connection keep-alive and efficient transport: Ensure that the overhead of making requests to the model is minimized. For example, use persistent connections or gRPC streaming to avoid HTTP setup latency for each request. If your voice agent architecture has separate services (STTservice, LLM service, TTS service), make sure they are long-lived and reuse connections so you’re not negotiating new network handshakes each time. In practice, gRPC with bidirectional streaming is a popular choice for voice pipelines because it allows audio, text, and tokens to flow with low overhead continuously, rather than a start-stop HTTP pattern.