Teaching domain knowledge to AI systems
This is part 1 of a series of posts I plan on writing on how do you teach your AI systems domain specific knowledge.
Vertical AI companies differentiate themselves by their ability to deeply understand and address the nuances of specific industries, from healthcare to finance to manufacturing. While general purpose LLMs can handle a wide variety of tasks, the real breakthroughs in efficiency and accuracy emerge when these systems are infused with domain specific knowledge. This process of identifying industry/company practices, terminologies, workflows and integrating all this expertise into their AI systems plays a big part in improving the quality of the product and thereby the success of the company. The crux of this exercise lies in recognising what critical information must be captured, at what intervals, how it should be stored and how often it should be updated.
How to Represent Domain Knowledge
The representation of domain knowledge can follow multiple paths, each with its own trade-offs. Organisations can embed the knowledge graphs and rules directly into the model by fine tuning on carefully curated datasets. While some industries do require this approach, this level of optimisation might be an overkill and could lead to added complexities. Fine tuning is ideal if you want your AI system to talk or act in a certain domain specific way but not if you just want to teach some knowledge and workflows to the model.
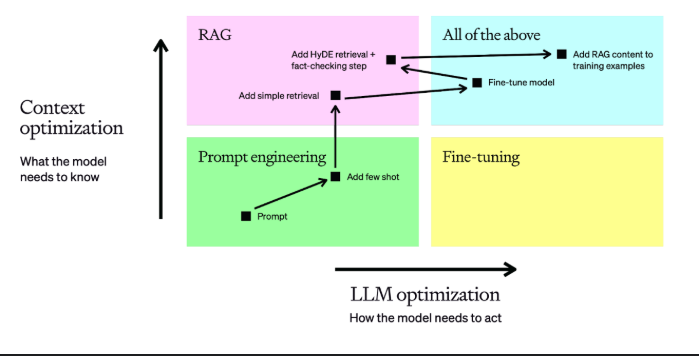
Another more relevant way to approach this is to inject the domain knowledge dynamically during inference. Companies usually use a mix of prompt engineering and RAG where they use knowledge graphs to structure their domain expertise and then tapping into those graphs at run time. This allows the systems to populate their context with relevant and up to date information providing more helpful responses. Knowledge graphs can serve as the semantic layer for these kind of systems, providing explicit definitions of entities and relationships that mirror the companies understanding.
These knowledge graphs should be viewed as tools for sharpening the semantic understanding of the LLMs and not just for aggregating and dumping the data into the context window. The key question becomes: “What is the minimum required knowledge for my specific use-case?” Rather than attempting to structure every entity, concept and relationship within a company, you should focus on creating domain ontologies where lack of structure/information would make the AI system fail for the given task. This might mean implementing document hierarchies, concept nodes linked to vector chunks, or document summaries coded into the graph structures. This process usually starts with understanding the business objectives and collecting the required datasets, cleaning and structuring it into a knowledge graph, designing the agent/RAG system to integrate with existing workflows and setting up the whole pipeline to ensure your systems always work on top of the latest and up to date information.
Once domain knowledge is codified, effectively using it within AI agent workflows can significantly boost performance and trustworthiness. Injecting domain specific prompts helps reduce ambiguous or inaccurate responses, while real time retrieval from knowledge graphs or validated data stores minimises hallucinations and improves agent accuracy. Crucially, this domain focussed approach also improves transparency as knowledge graphs provide an auditable trail for the AI’s reasoning process.
Effectively codifying domain expertise also requires strategic timing decisions. Pre-training on specialised datasets builds foundational knowledge but is resource-intensive, while fine tuning offers targeted refinement which may not be always necessary. Runtime augmentation of context through knowledge graphs enables the agent system to always stay up to date with the current company practices, workflows and standards.
As company evolves and processes change, the knowledge graph or domain ontology must be continually refreshed to maintain accuracy. Vertical AI companies that invest in repeatable methodologies for harvesting new knowledge, validating its correctness, and integrating it into AI systems will sustain a competitive edge here.