Diffusion models are interesting
I stumbled across this tweet a week or so back where this company called Inception Labs released a Diffusion LLM (dLLM). Instead of being autoregressive and predicting tokens left to right, here you start all at once and then gradually come up with sensible words simultaneously (start/finish/middle etc. all at once). Something which worked historically for image and video models is now outperforming similar-sized LLMs in code generation.
- The company also claims 5-10x improvement across speed and efficiency

Why are they interesting to me?
After spending the better part of the last 2 years reading, writing, and working in LLM evaluation, I see some obvious first-hand benefits for this paradigm:
Traditional LLMs hallucinate. It’s like they are confidently spitballing text while actually making up facts on the go. This is why they start sentences super confidently sometimes only to suggest something stupid in the end. dLLMs can generate certain important portions first, validate it, and then continue the rest of the generation.
- Ex: A CX chatbot would first generate the policy version number, validate it before advising a customer about a potentially hallucinated policy.
Agents might get better. Multi-step agentic workflows may not get stuck in loops using dLLMs. Planning, reasoning, and self-correction are a crucial part of agent flows, and we might currently be bottlenecked due to the LLM architecture. dLLMs could solve for this by ensuring that the entire plan top to bottom stays coherent. It’s like seeing ahead in the future for a little bit (based on whatever context you have) and then ensuring you don’t get stuck.
Here is a look at a more recent model responding to the prompt “Explain Game theory” to me. You can notice the last part of the sentences are generated before the middle. It’s quite fun to run some queries and see which words get generated first.
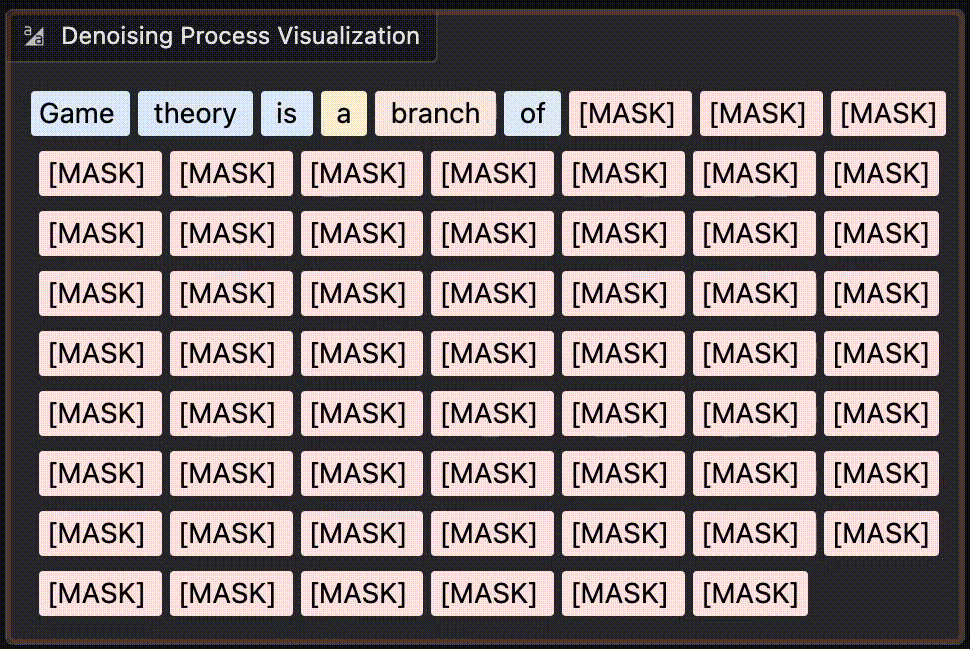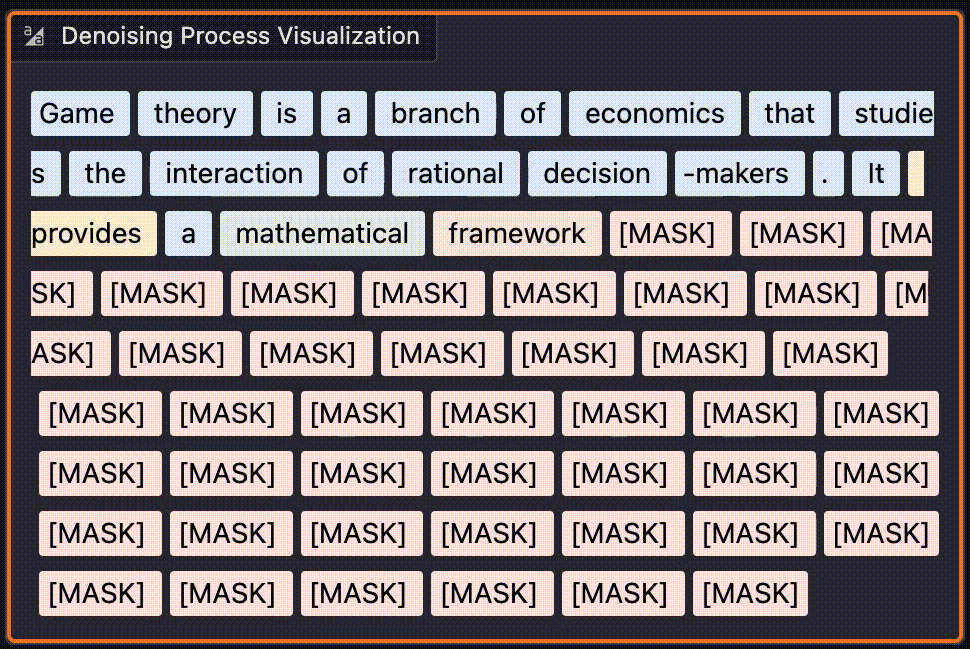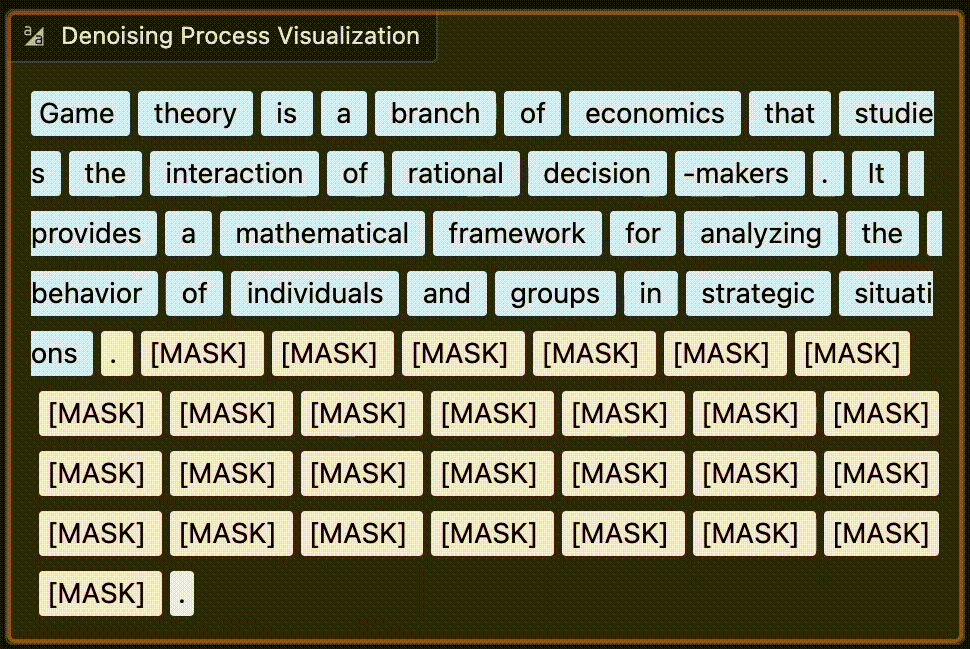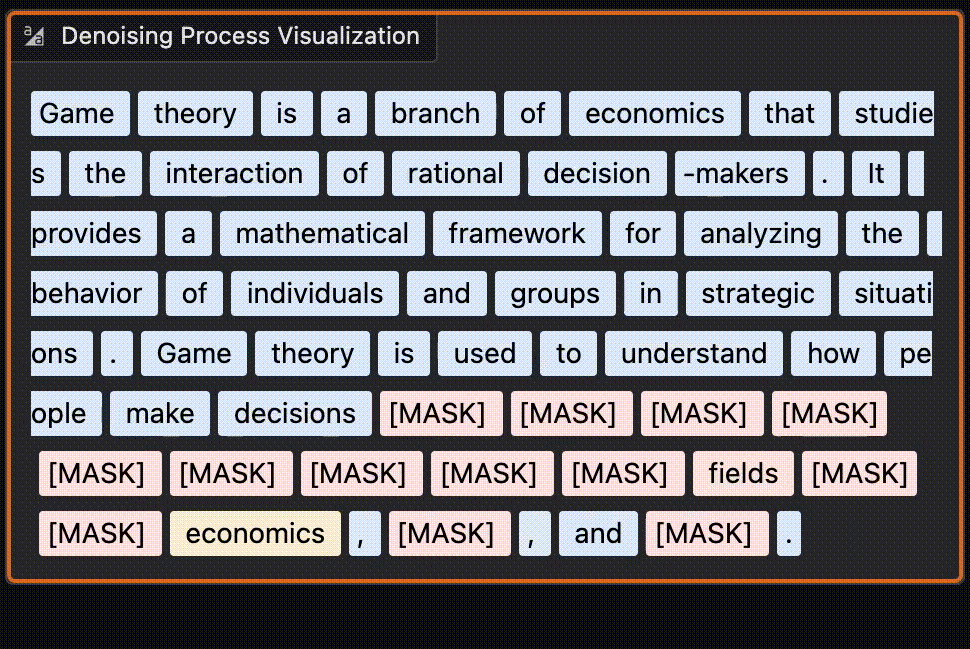
You can try it yourself here on HF.