AI Alignment - Weak-to-strong generalization (W2SG) explained
AI alignment is a broad topic of research to basically ponder over the question “How can AI systems be steered to accomplish the human intended goals and preferences?”. Simply put, how do we make sure that the AGI will listen to us? Currently, we use methods like RLHF to steer our large language models. However, future AI systems will be capable of extremely complex and creative behaviors that will make it hard for humans to reliably supervise them. They will be generating millions of lines of code or generating novels with thousands of words. Can we supervise a superhuman AI using only human supervisors We are currently uncertain about this and don’t exactly know if the current methods will scale to super human model. So, OpenAI decided to study an interesting analogy where they try to supervise(align) a larger model GPT-4 using a smaller model GPT-2. The GPT-2 is analogous to a human(a weak supervisor) and they experiment with a bunch of setups to see if it can reliably steer GPT-4. A direct fine tune is still the best approach possible(today for GPT-4 type model) but we will need to invent/explore new methodologies to steer potential AGI and this blog post is about that paper.
Before going further, lets first understand the setups used:
Weak supervisor
This is nothing but a base GPT-2 model fine tuned on certain ground truth labels like the Ethics datasets, Hellswag etc to create a fine tuned version of it. This fine tuned version(the weak supervisor) is then used to predict on a held-out set of examples on the ground truth dataset. This weak supervisor will then predict the labels and they are called “weak labels”.
Now, we train a strong model (base GPT-4 which is not fine tuned) with these weak labels generated by our weak supervisor to create a final strong student model(fine tuned GPT-4).

Strong Ceiling - The baseline for comparison
The above process is described further in the code they open sourced. They essentially do the following:
- Train a weak model on the first half of the dataset
- Train the strong model on the second of the training dataset with labels generated by the weak model
- Baseline: Strong Ceiling Train a strong model on the second half of the dataset

The new method - Auxillary confidence loss
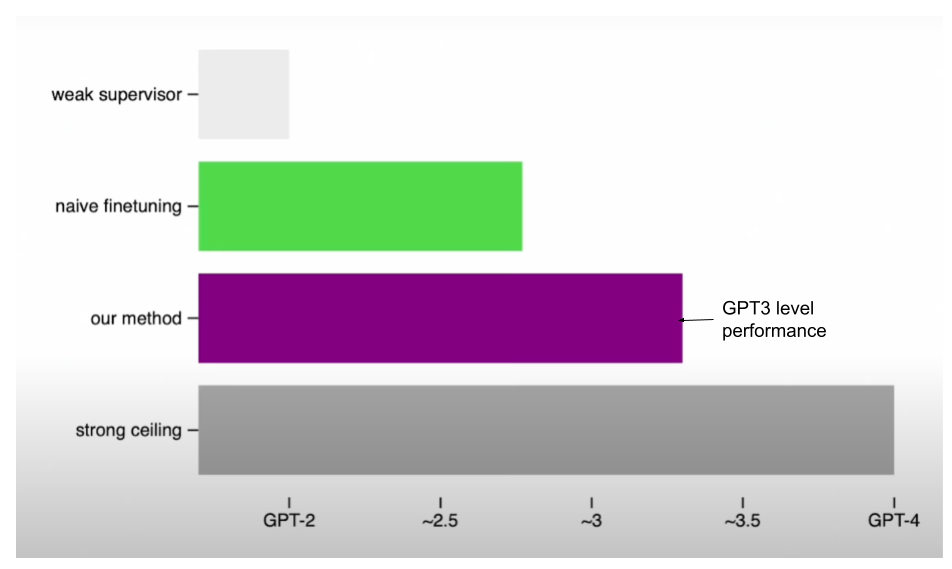
The new method proposed in the paper is basically a way to encourage the strong model(created in the weak supervisor step) to be more confident - including confidently disagreeing with the weak supervisor if necessary. When they supervise GPT-4 with a GPT-2 level model using this method on NLP tasks, they find that the resultant model performs somewhere between GPT-3 and GPT-3.5. They were also able to recover much of the GPT-4 capabilities with much weaker supervision. They do this by having some auxillary confidence loss which forces the model to be more confident. Check section A.4 of the paper for a detailed description of the method used. I have left out the exact description due to its slightly more mathematical nature.
Can small models supervise larger models?
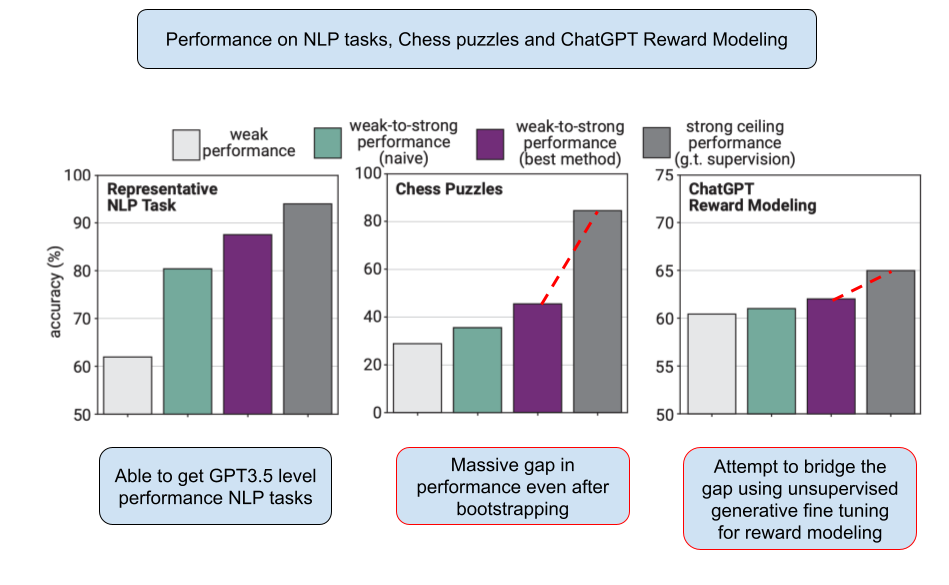
The answer is a mixed yes and a no. They were able to eke out GPT-3/3.5 level performance on NLP tasks as we see in the below graph but not so much on other tasks.
NLP benchmark using 4 different models (weak supervisor, naive fine tuning, their new method and strong ceiling) and performance is measured by looking at how different models perform on the same NLP task.
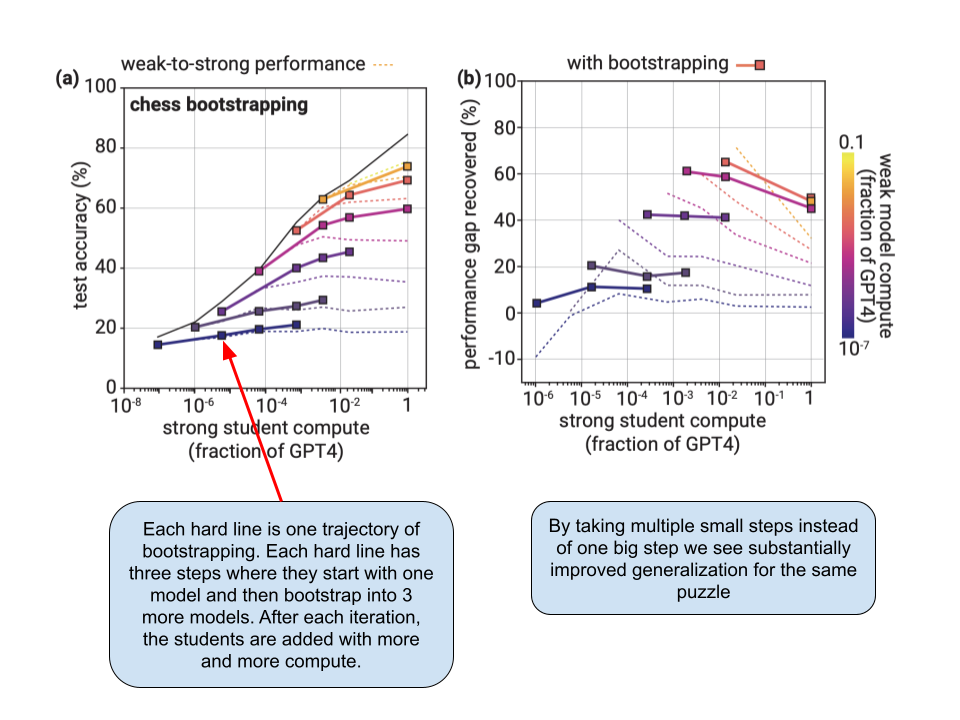
Bootstrapping for chess puzzles
In the paper, they use the above methods and do the comparison on three different tasks. First is the NLP benchmarks which we discussed above, second is chess puzzles and finally ChatGPT Reward modeling. This section details the bootstrapping used for chess puzzles.
In the pre-training dataset they already had chess games but in the fine tuning dataset they now had chess puzzles. You basically are fed the board state as a text prompt and the model has to predict the best next move as a text label. Their experiment setup didn’t allow feeding images of the chess board.
However, they found out that naive fine tuning doesn’t really work well for chess puzzles and the gap between student and supervisor is too large. Thats why they introduce “Bootstrapping” to solve this problem. Bootstrapping is a long-standing idea in alignment where instead of directly aligning very superhuman models, you could first align an only slightly superhuman model, use that to align an even smarter model, and so on until you align the model you want for your experiment. They construct a sequence of model sizes M1 → M2 → . . . → Mn of increasing sizes. Then, they use the weak labels from M1 to fine tune M2, use M2 to generate new weak labels that you can use to fine tune the next model in the sequence, M3, and so on.
ChatGPT Reward Modeling
The standard approach to aligning models today is reinforcement learning from human feedback (RLHF). A critical step of RLHF is to train a reward model (RM) to predict human preferences between model responses. Specifically, a reward model is trained on a dataset consisting of dialogs between a human and an assistant model. For each query, the humans compare multiple possible responses (completions) from the assistant, providing human preference data. Then, a reward model is trained to predict the results of pairwise comparisons between completions. Finally, the assistant model(the chatbot like ChatGPT) is trained by optimizing against the reward model with reinforcement learning (RL).
As we saw in the previous section, our strong ceiling model still outperforms our confidence boosted strong student model. How did they attempt to bridge this gap? To solve this they used unsupervised generative fine tuning for the reward modeling. Its just a way to increase the salience of a task without using ground truth labels. In this case they perform unsupervised fine tuning with data relevant to the task. They take the ChatGPT comparison data and they ignore the human preferences. What you are left with is just the prefix-completion pairs.
However, this poses an interesting question. Isn’t it cheating to use the ChatGPT comparison data instead of using a new supervision dataset? However, since they compare performance to the strong ceiling model which was also generatively fine tuned using the same dataset(ChatGPT comparison) its fine to do this. GPT-4 was first fine tuned with ChatGPT comparison data without human preferences and then was fine tuned with the dataset of human preferences. So, even comparing to this strong ceiling they were to able to recover the performance gap by about 10-20%.
Conclusion
As we see above, they used three techniques to achieve some sort of weak-to-strong generalization.
- Auxillary confidence loss
- Bootstrapping for chess puzzles
- Unsupervised generative fine tuning for reward modeling
However, none of the methods work for every situation. Collectively, their results suggest that naive human supervision—such as reinforcement learning from human feedback (RLHF)—could scale poorly to superhuman models without further work, but it is feasible to substantially improve weak-to-strong generalization. And they call out two problems which may arise if and when humans try to align super human models which they mention as “disanalogies”. They are:
- Imitation Saliency: Superhuman models may easily imitate weak errors from human supervisors but might have harder time imitating weak errors from AI supervisors. This is mainly because human errors are basically all over the pre-training data of current LLMs. More generally, the types of errors weak models make today may be different from the types of errors humans will make when attempting to supervise superhuman models. This makes generalization of the above methods much harder.

- Pre-training leakage: Superhuman knowledge may be latent and not observable. In the paper, they elicit knowledge from the strong model using certain tasks like SciQ NLP. However, its possible that these tasks are already part of the pre-training data but just framed differently. This will overall make weak-to-strong generalization easier for strong models and make results look better than they are. However, in the future we might have models which are entirely built through self-supervised learning or reinforcement learning (rather than through imitation learning) but we don’t such an AI just yet.
If you liked my post, let me know on Twitter. Other posts on AI:
Further reading and sources:
- Combining W2SG with other alignment techniques
- W2SG paper and the Github repo
- AI Alignment Forum and the relevant post detailing other approaches to solve the same problem
- Lesswrong discussion on the paper